
Kube-Scheduler源码阅读
从K8S调度器的角度来看集群中的资源
Kube-Scheduler源码阅读
版本: v1.20
参考列表:
- 《Kubernetes源码剖析》——郑东旭
- kube-scheduler源码分析
想要解决的问题
- Kube-Scheduler为Pod分配Node时,对Node内的信息有无指定
- 当分配完成,Pod和Node有一一对应时,如何将Node内的指定资源分配给Pod
- CPU资源如何实现挂载
Scheduler基本流程
Scheduler作为一种组件
Scheduler的目标就是为一堆Pod寻找匹配的Node,Scheduler不会单次匹配所有Pod,而是依次匹配每一个Pod。在为某个Pod寻找匹配Node时,会先进行一次predicates ,过滤资源不满足的Node,然后执行priorities 为所有Node打分,最后从所有Node中选取得分最高的节点,所谓当前Pod的匹配节点。
Scheduler源码阅读
Scheduler的启动
在我看到的路径中(cmd/kube-schduler/app/server.go)Scheduler作为一个独立的插件进行启动,需要通过控制台命令进行启动。
runCommand
// runCommand runs the scheduler.
func runCommand(cmd *cobra.Command, opts *options.Options, registryOptions ...Option) error {
verflag.PrintAndExitIfRequested()
cliflag.PrintFlags(cmd.Flags())
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
cc, sched, err := Setup(ctx, opts, registryOptions...)
if err != nil {
return err
}
return Run(ctx, cc, sched)
}
这里主要经过了两个步骤:
- 使用
Setup函数根据传入的参数和选项生成一个schduler - 调用
Run方法,运行生成的schduler
Run
// Run executes the scheduler based on the given configuration. It only returns on error or when context is done.
func Run(ctx context.Context, cc *schedulerserverconfig.CompletedConfig, sched *scheduler.Scheduler) error {
...
// 运行`EventBroadcaster`事件管理器
// Prepare the event broadcaster.
cc.EventBroadcaster.StartRecordingToSink(ctx.Done())
// 运行http或https接口
// Setup healthz checks.
var checks []healthz.HealthChecker
if cc.ComponentConfig.LeaderElection.LeaderElect {
checks = append(checks, cc.LeaderElection.WatchDog)
}
waitingForLeader := make(chan struct{})
isLeader := func() bool {
select {
case _, ok := <-waitingForLeader:
// if channel is closed, we are leading
return !ok
default:
// channel is open, we are waiting for a leader
return false
}
}
// Start up the healthz server.
if cc.InsecureServing != nil {
separateMetrics := cc.InsecureMetricsServing != nil
handler := buildHandlerChain(newHealthzHandler(&cc.ComponentConfig, cc.InformerFactory, isLeader, separateMetrics, checks...), nil, nil)
if err := cc.InsecureServing.Serve(handler, 0, ctx.Done()); err != nil {
return fmt.Errorf("failed to start healthz server: %v", err)
}
}
if cc.InsecureMetricsServing != nil {
handler := buildHandlerChain(newMetricsHandler(&cc.ComponentConfig, cc.InformerFactory, isLeader), nil, nil)
if err := cc.InsecureMetricsServing.Serve(handler, 0, ctx.Done()); err != nil {
return fmt.Errorf("failed to start metrics server: %v", err)
}
}
if cc.SecureServing != nil {
handler := buildHandlerChain(newHealthzHandler(&cc.ComponentConfig, cc.InformerFactory, isLeader, false, checks...), cc.Authentication.Authenticator, cc.Authorization.Authorizer)
// TODO: handle stoppedCh returned by c.SecureServing.Serve
if _, err := cc.SecureServing.Serve(handler, 0, ctx.Done()); err != nil {
// fail early for secure handlers, removing the old error loop from above
return fmt.Errorf("failed to start secure server: %v", err)
}
}
// 运行所有已经实例化的Informer对象
// Start all informers.
cc.InformerFactory.Start(ctx.Done())
// Wait for all caches to sync before scheduling.
cc.InformerFactory.WaitForCacheSync(ctx.Done())
// 领导者选举实例化
// If leader election is enabled, runCommand via LeaderElector until done and exit.
if cc.LeaderElection != nil {
cc.LeaderElection.Callbacks = leaderelection.LeaderCallbacks{
OnStartedLeading: func(ctx context.Context) {
close(waitingForLeader)
sched.Run(ctx)
},
OnStoppedLeading: func() {
klog.Fatalf("leaderelection lost")
},
}
leaderElector, err := leaderelection.NewLeaderElector(*cc.LeaderElection)
if err != nil {
return fmt.Errorf("couldn't create leader elector: %v", err)
}
leaderElector.Run(ctx)
return fmt.Errorf("lost lease")
}
// Leader election is disabled, so runCommand inline until done.
close(waitingForLeader)
sched.Run(ctx)
return fmt.Errorf("finished without leader elect")
}
Run函数主要完成了以下事务:
- 运行
EventBroadcaster事件管理器,这个事件管理器用于将kube-scheduler组件中发生的事件上报给Kubernetes APIServer - 运行http或https接口,其中开放了以下几个接口:
healthz:健康检查接口metrics:用于监控指标,指标采集debug/pprof:用于性能分析
- 运行所有已经实例化的Informer对象,用于监控各种Informer
- 领导者选举实例化:
kuber-scheduler作为一个插件,存在多个副本,所有副本都会不断的尝试去获取锁,获取到锁的副本,会成为leader。如果某个正在运行的leader因为某种原因退出,或是锁丢失,那么其他副本就会去竞争,并且成为新的leader,这样就会保证系统的高可靠性。 sched.Run(ctx)运行调度器
如何运行起来Schduler并不是今天了解的重点,所以我们简单的了解中间经过的过程即可。总的来说:
- Kuber-Scheduler作为一个独立的插件运行,可以存在多个副本
- Kuber-Scheduler会在进行操作时向API-Server报告
- Kuber-scheduler会通过Informer进行监控
Scheduler的资源分配
Scheduler结构
首先,我们来看Scheduler的结构:
type Scheduler struct {
SchedulerCache internalcache.Cache
Algorithm core.ScheduleAlgorithm
NextPod func() *framework.QueuedPodInfo
Error func(*framework.QueuedPodInfo, error)
StopEverything <-chan struct{}
SchedulingQueue internalqueue.SchedulingQueue
Profiles profile.Map
client clientset.Interface
}
在当前阶段,需要重点了解的是:SchedulingQueue,我们来看一下他的声明:
type PriorityQueue struct {
...
activeQ *heap.Heap
podBackoffQ *heap.Heap
unschedulableQ *UnschedulablePodsMap
...
}
这里重点关注的是,这个PriorityQueue实现了internalqueue.SchedulingQueue这个接口,在这个Queue中维护了三个堆:
activeQ:记录了正在调度的Pod的集合podBackoffQ:已经尝试并且确定为不可调度的PodunschedulableQ:从无法调度的队列移出的Pod
sched.Run
接着上一小节中的 sched.Run(ctx)运行调度器,在这一步中:
// Run begins watching and scheduling. It starts scheduling and blocked until the context is done.
func (sched *Scheduler) Run(ctx context.Context) {
sched.SchedulingQueue.Run()
wait.UntilWithContext(ctx, sched.scheduleOne, 0)
sched.SchedulingQueue.Close()
}
会启动刚才说明过的SchedulingQueue并且开启sched.scheduleOne,这个sched.scheduleOne函数会不断执行,直到ctx中传来终止信号。
sched.scheduleOne(对单个pod的调度)
这个函数太长了,这里就不贴代码了
该函数的过程可以用下图来理解:
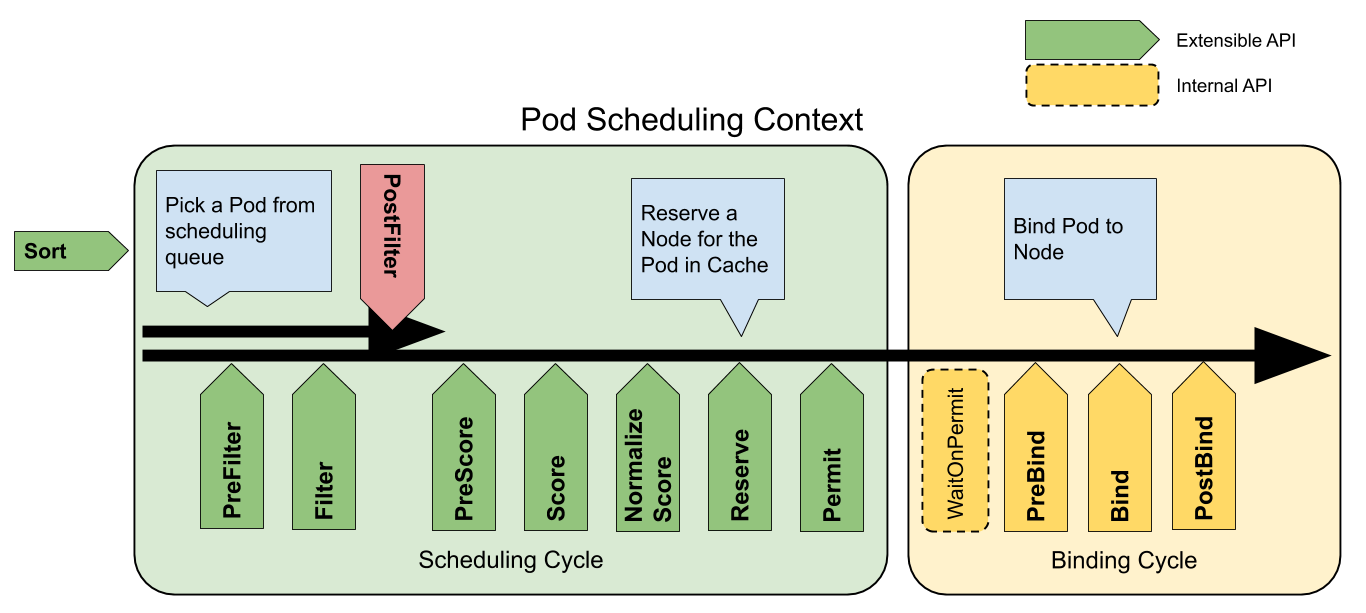
上图中绿色的部分用于确定Pod在哪个节点上运行,黄色部分用于将该策略应用于集群,执行绑定操作
该函数每次会对一个Pod进行调度(这个函数是我们关注的重点),他的执行流程如下:
- 从sched中使用
NextPod()函数取出一个待调度的Pod - 获取调度方法,并且判断是否需要跳过此次调度,如果不需要跳过则继续执行
- 运行
sched.Algorithm.Schedule函数,获取调度节点。当节点调度失败时,会返回error,这说明pod已经无法容纳在任何主机上,因此会开启抢占机制:所谓抢占机制,指的就是没有分配成功的pod会不断地请求相应的资源,在请求成功时第一时间就位。 - 触发
Reserve以及Permit流程(这俩是干啥的到现在还没看懂) - 执行Bind操作
(ASK)Reserve和Permit流程是干啥的
(ANSWER)Reserve:在绑定周期之前选择保留的节点; Permit: 批准或拒绝调度周期的结果
重点之Schedule()
func (g *genericScheduler) Schedule(ctx context.Context, fwk framework.Framework, state *framework.CycleState, pod *v1.Pod) (result ScheduleResult, err error) {
trace := utiltrace.New("Scheduling", utiltrace.Field{Key: "namespace", Value: pod.Namespace}, utiltrace.Field{Key: "name", Value: pod.Name})
defer trace.LogIfLong(100 * time.Millisecond)
if err := g.snapshot(); err != nil {
return result, err
}
trace.Step("Snapshotting scheduler cache and node infos done")
if g.nodeInfoSnapshot.NumNodes() == 0 {
return result, ErrNoNodesAvailable
}
feasibleNodes, diagnosis, err := g.findNodesThatFitPod(ctx, fwk, state, pod)
if err != nil {
return result, err
}
trace.Step("Computing predicates done")
if len(feasibleNodes) == 0 {
return result, &framework.FitError{
Pod: pod,
NumAllNodes: g.nodeInfoSnapshot.NumNodes(),
Diagnosis: diagnosis,
}
}
// When only one node after predicate, just use it.
if len(feasibleNodes) == 1 {
return ScheduleResult{
SuggestedHost: feasibleNodes[0].Name,
EvaluatedNodes: 1 + len(diagnosis.NodeToStatusMap),
FeasibleNodes: 1,
}, nil
}
priorityList, err := g.prioritizeNodes(ctx, fwk, state, pod, feasibleNodes)
if err != nil {
return result, err
}
host, err := g.selectHost(priorityList)
trace.Step("Prioritizing done")
return ScheduleResult{
SuggestedHost: host,
EvaluatedNodes: len(feasibleNodes) + len(diagnosis.NodeToStatusMap),
FeasibleNodes: len(feasibleNodes),
}, err
}
该函数会先执行:
findNodesThatFitPod函数,筛选得到符合基本资源需求的节点列表feasibleNodes,如果该列表长度为0那么返回错误,如果为1那么直接返回随后调用
prioritizeNodes函数进行评分,评分后会获取到每个结点的分数列表priorityList最终,执行
selectHost,从priorityList中选取一个节点,作为最终选择的节点priorityList是一个列表,其中的每一个元素都对应着一个节点的名称(name)以及得分(sorce),selectHost执行过程中,会顺序扫描所有的元素,记录下来得分最高的节点的名称,如果出现同分的情况,会随机选取一个节点作为最终的结果
重点之bind处理
当scheduleOne函数中处理完Schedule步骤后,会进行Reserve以及、Permit的处理,结束后,会进行bind():
// bind the pod to its host asynchronously (we can do this b/c of the assumption step above).
go func() {
bindingCycleCtx, cancel := context.WithCancel(ctx)
defer cancel()
metrics.SchedulerGoroutines.WithLabelValues(metrics.Binding).Inc()
defer metrics.SchedulerGoroutines.WithLabelValues(metrics.Binding).Dec()
waitOnPermitStatus := fwk.WaitOnPermit(bindingCycleCtx, assumedPod)
if !waitOnPermitStatus.IsSuccess() {
var reason string
if waitOnPermitStatus.IsUnschedulable() {
metrics.PodUnschedulable(fwk.ProfileName(), metrics.SinceInSeconds(start))
reason = v1.PodReasonUnschedulable
} else {
metrics.PodScheduleError(fwk.ProfileName(), metrics.SinceInSeconds(start))
reason = SchedulerError
}
// trigger un-reserve plugins to clean up state associated with the reserved Pod
fwk.RunReservePluginsUnreserve(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
if forgetErr := sched.SchedulerCache.ForgetPod(assumedPod); forgetErr != nil {
klog.ErrorS(forgetErr, "scheduler cache ForgetPod failed")
}
sched.recordSchedulingFailure(fwk, assumedPodInfo, waitOnPermitStatus.AsError(), reason, "")
return
}
// Run "prebind" plugins.
preBindStatus := fwk.RunPreBindPlugins(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
if !preBindStatus.IsSuccess() {
metrics.PodScheduleError(fwk.ProfileName(), metrics.SinceInSeconds(start))
// trigger un-reserve plugins to clean up state associated with the reserved Pod
fwk.RunReservePluginsUnreserve(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
if forgetErr := sched.SchedulerCache.ForgetPod(assumedPod); forgetErr != nil {
klog.ErrorS(forgetErr, "scheduler cache ForgetPod failed")
}
sched.recordSchedulingFailure(fwk, assumedPodInfo, preBindStatus.AsError(), SchedulerError, "")
return
}
err := sched.bind(bindingCycleCtx, fwk, assumedPod, scheduleResult.SuggestedHost, state)
if err != nil {
metrics.PodScheduleError(fwk.ProfileName(), metrics.SinceInSeconds(start))
// trigger un-reserve plugins to clean up state associated with the reserved Pod
fwk.RunReservePluginsUnreserve(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
if err := sched.SchedulerCache.ForgetPod(assumedPod); err != nil {
klog.ErrorS(err, "scheduler cache ForgetPod failed")
}
sched.recordSchedulingFailure(fwk, assumedPodInfo, fmt.Errorf("binding rejected: %w", err), SchedulerError, "")
} else {
// Calculating nodeResourceString can be heavy. Avoid it if klog verbosity is below 2.
if klog.V(2).Enabled() {
klog.InfoS("Successfully bound pod to node", "pod", klog.KObj(pod), "node", scheduleResult.SuggestedHost, "evaluatedNodes", scheduleResult.EvaluatedNodes, "feasibleNodes", scheduleResult.FeasibleNodes)
}
metrics.PodScheduled(fwk.ProfileName(), metrics.SinceInSeconds(start))
metrics.PodSchedulingAttempts.Observe(float64(podInfo.Attempts))
metrics.PodSchedulingDuration.WithLabelValues(getAttemptsLabel(podInfo)).Observe(metrics.SinceInSeconds(podInfo.InitialAttemptTimestamp))
// Run "postbind" plugins.
fwk.RunPostBindPlugins(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
}
}()
这一部分是我们关注的重点,因为我的目标是通过DevidcePlugiun的形式自定义cpu资源以及gpu资源,进行分配。
绑定操作可以分为四个步骤:
首先,会等待Pod被Permit后才会执行
bind操作prebind:会执行用户自定义的prebind插件Bind:将Pod绑定在节点上PostBind:运行用户自定义的postBind插件
bind处理中的bind()函数
bind()函数会:
- 先对扩展插件进行绑定
extendersBinding - 再对固有插件进行绑定
RunBindPlugins - 在结束时,运行:
finishBinding
extendersBinding(自定义extender Bind方法):
func (sched *Scheduler) extendersBinding(pod *v1.Pod, node string) (bool, error) {
for _, extender := range sched.Algorithm.Extenders() {
if !extender.IsBinder() || !extender.IsInterested(pod) {
continue
}
return true, extender.Bind(&v1.Binding{
ObjectMeta: metav1.ObjectMeta{Namespace: pod.Namespace, Name: pod.Name, UID: pod.UID},
Target: v1.ObjectReference{Kind: "Node", Name: node},
})
}
return false, nil
}
对于所有扩展,如果没有被定义为Bind method,或该扩展程序没有管理该Pod请求的扩展资源,那么就会忽略该extender。
否则,将此次Bind操作的权限委托给extender进行。
RunBindPlugins:
在默认情况下,这里的BindPlugins是DefaultBinder:
// Bind binds pods to nodes using the k8s client.
func (b DefaultBinder) Bind(ctx context.Context, state *framework.CycleState, p *v1.Pod, nodeName string) *framework.Status {
klog.V(3).InfoS("Attempting to bind pod to node", "pod", klog.KObj(p), "node", nodeName)
binding := &v1.Binding{
ObjectMeta: metav1.ObjectMeta{Namespace: p.Namespace, Name: p.Name, UID: p.UID},
Target: v1.ObjectReference{Kind: "Node", Name: nodeName},
}
err := b.handle.ClientSet().CoreV1().Pods(binding.Namespace).Bind(ctx, binding, metav1.CreateOptions{})
if err != nil {
return framework.AsStatus(err)
}
return nil
}
DefaultBinder中,会调用 b.handle.ClientSet().CoreV1().Pods(binding.Namespace).Bind(ctx, binding, metav1.CreateOptions{})完成绑定。
其中,此处调用的Bind方法定义如下:
// Bind applies the provided binding to the named pod in the current namespace (binding.Namespace is ignored).
func (c *pods) Bind(ctx context.Context, binding *v1.Binding, opts metav1.CreateOptions) error {
return c.client.Post().Namespace(c.ns).Resource("pods").Name(binding.Name).VersionedParams(&opts, scheme.ParameterCodec).SubResource("binding").Body(binding).Do(ctx).Error()
}
可以看到,这里实质上就是向某处发送了一次POST请求,至于到底在请求什么,这点我们不得而知,但是可以确认的是,该请求在向Node节点中的Kubelet发送,请求的目标是,让Kubelet节点内完成绑定操作,并且返回绑定结果。
至此为止,scheduler部分我们已经了解清楚了,总体来说:当需要调度资源时,scheduler会依次为每个Pod进行调度,调度时:
- 根据需求对所有Node进行筛选,保留满足需求的Node
- 对剩余的Node进行评分,并且对评分进行标准化
- 找到评分最高的Node,选为当前Pod部署的目标节点
- 进行Reserve、Permit操作
- 进入Bind阶段,分别执行Prebind,bind,postbind,完成绑定
绑定阶段Kubelet与APIServer的通信
到此为止,我们来梳理一下自己的认知:
- Kubelet会与DevicePlugin通信,实时维护节点内的DevicePlugin信息
- Scheduler会与Kubelet通信,维护哥哥节点内的DevicePlugin信息
- 在部署Pod时,Scheduler只能将Pod与Node进行匹配,具体的部署事宜是由Kubelet完成的
Kubelet.HandlePodUpdates
// HandlePodUpdates is the callback in the SyncHandler interface for pods
// being updated from a config source.
func (kl *Kubelet) HandlePodUpdates(pods []*v1.Pod) {
start := kl.clock.Now()
for _, pod := range pods {
kl.podManager.UpdatePod(pod)
if kubetypes.IsMirrorPod(pod) {
kl.handleMirrorPod(pod, start)
continue
}
mirrorPod, _ := kl.podManager.GetMirrorPodByPod(pod)
kl.dispatchWork(pod, kubetypes.SyncPodUpdate, mirrorPod, start)
}
}
这个函数会调用kubelet.dispatchWork,该函数如下:
// dispatchWork starts the asynchronous sync of the pod in a pod worker.
// If the pod has completed termination, dispatchWork will perform no action.
func (kl *Kubelet) dispatchWork(pod *v1.Pod, syncType kubetypes.SyncPodType, mirrorPod *v1.Pod, start time.Time) {
// check whether we are ready to delete the pod from the API server (all status up to date)
containersTerminal, podWorkerTerminal := kl.podAndContainersAreTerminal(pod)
if pod.DeletionTimestamp != nil && containersTerminal {
klog.V(4).Infof("Pod %q has completed execution and should be deleted from the API server: %s", format.Pod(pod), syncType)
kl.statusManager.TerminatePod(pod)
return
}
// optimization: avoid invoking the pod worker if no further changes are possible to the pod definition
// (i.e. the pod has completed and its containers have been terminated)
if podWorkerTerminal && containersTerminal {
klog.V(4).InfoS("Pod has completed and its containers have been terminated, ignoring remaining sync work", "pod", klog.KObj(pod), "syncType", syncType)
return
}
// Run the sync in an async worker.
kl.podWorkers.UpdatePod(&UpdatePodOptions{
Pod: pod,
MirrorPod: mirrorPod,
UpdateType: syncType,
OnCompleteFunc: func(err error) {
if err != nil {
metrics.PodWorkerDuration.WithLabelValues(syncType.String()).Observe(metrics.SinceInSeconds(start))
}
},
})
// Note the number of containers for new pods.
if syncType == kubetypes.SyncPodCreate {
metrics.ContainersPerPodCount.Observe(float64(len(pod.Spec.Containers)))
}
}
该函数调用了:kl.podWorkers.UpdatePod,这个函数非常重要:
// Apply the new setting to the specified pod.
// If the options provide an OnCompleteFunc, the function is invoked if the update is accepted.
// Update requests are ignored if a kill pod request is pending.
func (p *podWorkers) UpdatePod(options *UpdatePodOptions) {
...
p.podLock.Lock()
defer p.podLock.Unlock()
if podUpdates, exists = p.podUpdates[uid]; !exists {
// We need to have a buffer here, because checkForUpdates() method that
// puts an update into channel is called from the same goroutine where
// the channel is consumed. However, it is guaranteed that in such case
// the channel is empty, so buffer of size 1 is enough.
podUpdates = make(chan UpdatePodOptions, 1)
p.podUpdates[uid] = podUpdates
// Creating a new pod worker either means this is a new pod, or that the
// kubelet just restarted. In either case the kubelet is willing to believe
// the status of the pod for the first pod worker sync. See corresponding
// comment in syncPod.
go func() {
defer runtime.HandleCrash()
p.managePodLoop(podUpdates)
}()
}
...
}
这里在结束时,会调用p.managePodLoop(podUpdates):
func (p *podWorkers) managePodLoop(podUpdates <-chan UpdatePodOptions) {
var lastSyncTime time.Time
for update := range podUpdates {
err := func() error {
podUID := update.Pod.UID
// This is a blocking call that would return only if the cache
// has an entry for the pod that is newer than minRuntimeCache
// Time. This ensures the worker doesn't start syncing until
// after the cache is at least newer than the finished time of
// the previous sync.
status, err := p.podCache.GetNewerThan(podUID, lastSyncTime)
if err != nil {
// This is the legacy event thrown by manage pod loop
// all other events are now dispatched from syncPodFn
p.recorder.Eventf(update.Pod, v1.EventTypeWarning, events.FailedSync, "error determining status: %v", err)
return err
}
err = p.syncPodFn(syncPodOptions{
mirrorPod: update.MirrorPod,
pod: update.Pod,
podStatus: status,
killPodOptions: update.KillPodOptions,
updateType: update.UpdateType,
})
lastSyncTime = time.Now()
return err
}()
// notify the call-back function if the operation succeeded or not
if update.OnCompleteFunc != nil {
update.OnCompleteFunc(err)
}
if err != nil {
// IMPORTANT: we do not log errors here, the syncPodFn is responsible for logging errors
klog.Errorf("Error syncing pod %s (%q), skipping: %v", update.Pod.UID, format.Pod(update.Pod), err)
}
p.wrapUp(update.Pod.UID, err)
}
}
这个函数会遍历所有对Pod的更新,依次使用循环中的匿名函数执行,其中,具体负责执行的是:syncPodFn,这是一个成员变量,在kubelet初始化时会:
klet.podWorkers = newPodWorkers(
klet.syncPod, kubeDeps.Recorder, klet.workQueue, klet.resyncInterval, backOffPeriod, klet.podCache
)
这里的syncPod就是syncPodFn:
这个kubelet.syncPodFn非常的长,他的执行流程是:

这个函数实在是太长了,如果感兴趣可以在kubernetes/pkg/kubelet/kubelet.go文件夹下自行查看,其中有如下代码:
// Volume manager will not mount volumes for terminated pods
if !kl.podIsTerminated(pod) {
// Wait for volumes to attach/mount
if err := kl.volumeManager.WaitForAttachAndMount(pod); err != nil {
kl.recorder.Eventf(pod, v1.EventTypeWarning, events.FailedMountVolume, "Unable to attach or mount volumes: %v", err)
klog.Errorf("Unable to attach or mount volumes for pod %q: %v; skipping pod", format.Pod(pod), err)
return err
}
}
我们节选重要部分查看:
// Create Cgroups for the pod and apply resource parameters
// to them if cgroups-per-qos flag is enabled.
pcm := kl.containerManager.NewPodContainerManager()
// If pod has already been terminated then we need not create
// or update the pod's cgroup
if !kl.podIsTerminated(pod) {
// When the kubelet is restarted with the cgroups-per-qos
// flag enabled, all the pod's running containers
// should be killed intermittently and brought back up
// under the qos cgroup hierarchy.
// Check if this is the pod's first sync
firstSync := true
for _, containerStatus := range apiPodStatus.ContainerStatuses {
if containerStatus.State.Running != nil {
firstSync = false
break
}
}
// Don't kill containers in pod if pod's cgroups already
// exists or the pod is running for the first time
podKilled := false
if !pcm.Exists(pod) && !firstSync {
if err := kl.killPod(pod, nil, podStatus, nil); err == nil {
podKilled = true
} else {
klog.Errorf("killPod for pod %q (podStatus=%v) failed: %v", format.Pod(pod), podStatus, err)
}
}
// Create and Update pod's Cgroups
// Don't create cgroups for run once pod if it was killed above
// The current policy is not to restart the run once pods when
// the kubelet is restarted with the new flag as run once pods are
// expected to run only once and if the kubelet is restarted then
// they are not expected to run again.
// We don't create and apply updates to cgroup if its a run once pod and was killed above
if !(podKilled && pod.Spec.RestartPolicy == v1.RestartPolicyNever) {
if !pcm.Exists(pod) {
if err := kl.containerManager.UpdateQOSCgroups(); err != nil {
klog.V(2).Infof("Failed to update QoS cgroups while syncing pod: %v", err)
}
if err := pcm.EnsureExists(pod); err != nil {
kl.recorder.Eventf(pod, v1.EventTypeWarning, events.FailedToCreatePodContainer, "unable to ensure pod container exists: %v", err)
return fmt.Errorf("failed to ensure that the pod: %v cgroups exist and are correctly applied: %v", pod.UID, err)
}
}
}
}
在这里,我们创建了一个PodContainerManager,随后,如果节点不在终止状态那么就会进入该代码块中,在该代码块中,会使用pcm.EnsureExists(pod)创建一个cgroup,接下来看EnsureExists的代码:
// EnsureExists takes a pod as argument and makes sure that
// pod cgroup exists if qos cgroup hierarchy flag is enabled.
// If the pod level container doesn't already exist it is created.
func (m *podContainerManagerImpl) EnsureExists(pod *v1.Pod) error {
podContainerName, _ := m.GetPodContainerName(pod)
// check if container already exist
alreadyExists := m.Exists(pod)
if !alreadyExists {
// Create the pod container
containerConfig := &CgroupConfig{
Name: podContainerName,
ResourceParameters: ResourceConfigForPod(pod, m.enforceCPULimits, m.cpuCFSQuotaPeriod),
}
if m.podPidsLimit > 0 {
containerConfig.ResourceParameters.PidsLimit = &m.podPidsLimit
}
if err := m.cgroupManager.Create(containerConfig); err != nil {
return fmt.Errorf("failed to create container for %v : %v", podContainerName, err)
}
}
// Apply appropriate resource limits on the pod container
// Top level qos containers limits are not updated
// until we figure how to maintain the desired state in the kubelet.
// Because maintaining the desired state is difficult without checkpointing.
if err := m.applyLimits(pod); err != nil {
return fmt.Errorf("failed to apply resource limits on container for %v : %v", podContainerName, err)
}
return nil
}
实质上,这里会生成一组配置containerConfig,并且使用cgroupManager.Create方法,应用这个配置,以达到生成cgroup的目的。
我们的研究到此为止,因为再往下走还要走很深,实在没有时间再往底层追究了。
总结
最后,结合我们的目标总结一下今日的研究结果:
- 对于Scheduler而言,每次会完成一个Pod的匹配,为该Pod寻找最合适的Node进行匹配,自定义
DevicePlugin不会影响到Pod与Node的匹配结果 - Scheduler在找到匹配的Pod-Node后,会与对应的Node的Kubelet进行通信,Kubelet会完成Pod的创建,创建pod的过程中会根据配置使用linux的cgroup进行资源、设备的分配与部署