
图像处理(六)——单应性变换
图像如何进行旋转、平移、放大缩小等操作?这篇文章讲解起原理与实现
python图像处理笔记-六——单应性变换
齐次坐标
单应性变化是将一个平面内的店映射到另一个平面内的二维投影变换。本质上,单应性变换 H,按照下方的方程映射到二维的点:
我们也可以表示为:
对于图像平面内的点,齐次坐标是一个非常有用的表示方式。点的齐次坐标是依赖于其尺度定义的,所以以下三种表述实质上都在表示同一个二维点。
因此单应性矩阵H也仅依赖尺度定义,所以单应性矩阵具有八个独立的自由度。我们常用
仿射变换
在投影变换中,有一些特别重要的变换,如:仿射变换:
或者我们也可以写作:
我们来实现一下这个仿射变换的代码:
from PIL import Image
from numpy import *
from pylab import *
def normalize(points):
"""
在齐次坐标意义下:
对点进行归一化,使得最后一行为1
"""
for row in points:
row = points[-1]
return points
def makeHomog(points):
"""
将点集(dim * n)的数组转化为齐次坐标表示
"""
return vstack((points, ones((1, points.shape[1]))))
仿射变换
def flact(points, rtMatrix):
return np.dot(rtMatrix, points)
def plotPoints(points, color = None, line = True):
"""
给出一堆点,把他们画出来,并且显示
"""
for i in range(points.shape[1]):
if(color == None):
scatter(points[0][i], points[1][i])
else :
scatter(points[0][i], points[1][i], c= color[i])
if(line == False ):
return
for i in range(points.shape[1]):
nextPoint = (i + 1)%points.shape[1]
if(color == None):
plot([points[0][i],points[1][i]],[points[0][nextPoint],points[1][nextPoint]])
else:
plot([points[0][i],points[1][i]], [points[0][nextPoint],points[1][nextPoint]], c= color[i])
if name == 'main':
pointX = [0, 3, 3, 0]
pointY = [0, 0, 3, 3]
color = ['r','g','b','m']
Points = array([pointX, pointY])
Points = makeHomog(Points)
# 绘制变换之前的点
plotPoints(Points, color)
# 仿射变换矩阵
rtMatrix = array(
[[0.5,0,0],
[0,0.5,0],
[0,0,1]]
)
changedPoints = flact(Points, rtMatrix)
plotPoints(changedPoints, color)
show()
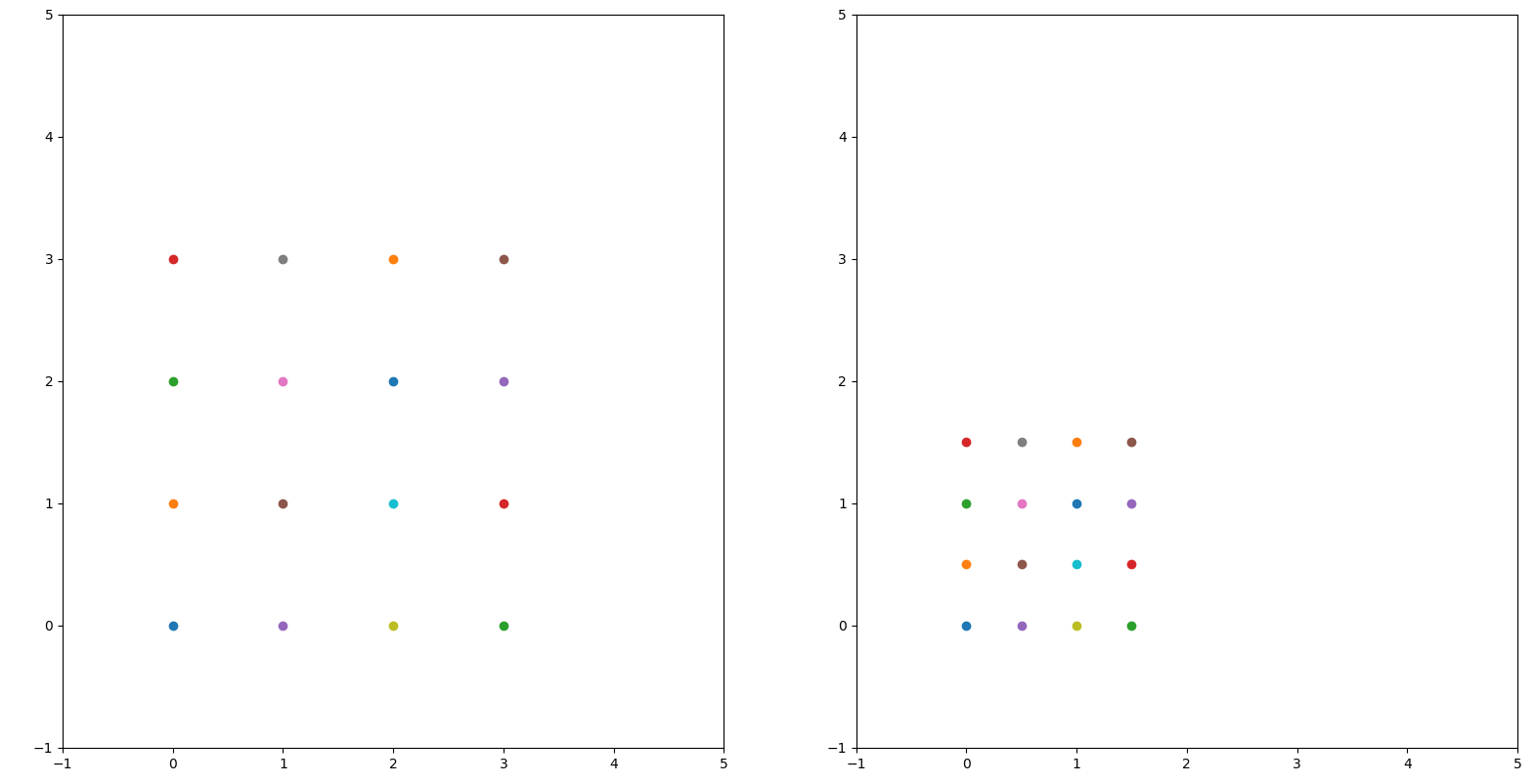 上面的图像中我们对左边的图像使用矩阵:
上面的图像中我们对左边的图像使用矩阵:
进行仿射变换,我们发现图像变小了,于是我们知道左边的A可以控制图像的大小。随后,我们将矩阵修改为:
 我们发现之前说的T能够控制图像的平移,实际上它还可以控制图像的旋转等,我在网上看到一张图,和大家分享一下:
我们发现之前说的T能够控制图像的平移,实际上它还可以控制图像的旋转等,我在网上看到一张图,和大家分享一下:
除此之外还有相似变换,相似变换是一种特殊的仿射变换,他描述了图像的旋转、平移、缩放,可以表示为:
直接线性变换算法
单应性矩阵可以由两幅图像中对应点计算出来。一个完全摄影变换有8个自由度。根据对应点约束,每个对应点可以写出两个方程,分别对应于
DLT(Diret Linear Transformation, 直接线性相似变化)是给定4个或者更多对应点对矩阵,来计算单应性矩阵H的方法。将单应性矩阵H作用在对应点上,重新写出该方程,我们可以得到下方方程:

我们可以看到,实际上用一组也可以解出结果,但是为了解的稳定,我们最好使用四组以上的特征匹配。方程的最小二乘解有一个既定的结论,即对A进行SVD分解,A的最小的奇异值对应的右奇异向量即是h的解。对h做reshape得到H。
直接线性变换算法在普通情况下,有八个自由度,而在解决仿射变换时,只有六个自由度,我们分别对两种情况写了代码:
from PIL import Image
from numpy import *
from pylab import *
def normalize(points):
"""
在齐次坐标意义下:
对点进行归一化,使得最后一行为1
"""
for row in points:
row = points[-1]
return points
def makeHomog(points):
"""
将点集(dim * n)的数组转化为齐次坐标表示
"""
return vstack((points, ones((1, points.shape[1]))))
仿射变换
def flact(points, rtMatrix):
return np.dot(rtMatrix, points)
def plotPoints(ax, points, color=None):
"""
给出一堆点,把他们画出来,并且显示
"""
xlim(-1, 5)
ylim(-1, 5)
for i in range(points.shape[1]):
if (color == None):
ax.scatter(points[0][i], points[1][i])
else:
ax.scatter(points[0][i], points[1][i], c=color[i])
def plotTwoPoints(points1, points2):
fig = figure()
ax1 = fig.add_subplot(1, 2, 1)
plotPoints(ax1, points1)
ax2 = fig.add_subplot(1, 2, 2)
plotPoints(ax2, points2)
show()
def hFromPoints(fp, tp):
"""
使用线性DLT,计算H,点自动进行归一化
输入:
fp : 起始点
tp : 经过H映射到的点
"""
# 形状不同
if fp.shape != tp.shape:
return RuntimeError('number of points do not match')
# 对点进行归一化处理
# 映射起始点
m = mean(fp[:2], axis=1)
maxstd = max(std(fp[:2], axis=1)) + 1e-9
C1 = diag([1 / maxstd, 1 / maxstd, 1])
C1[0][2] = -m[0] / maxstd
C1[1][2] = -m[1] / maxstd
fp = dot(C1, fp)
# 映射对应点
m = mean(tp[:2], axis=1)
maxstd = max(std(tp[:2], axis=1)) + 1e-9
C2 = diag([1 / maxstd, 1 / maxstd, 1])
C2[0][2] = -m[0] / maxstd
C2[1][2] = -m[1] / maxstd
tp = dot(C2, tp)
# 创建用于线性方法的矩阵,对于每个对应对,在矩阵中会出现两行数值
nbrCorreSponDences = fp.shape[1]
A = zeros((2 * nbrCorreSponDences, 9))
for i in range(nbrCorreSponDences):
A[2*i] = [-fp[0][i], -fp[1][i], -1, 0, 0, 0,
tp[0][i]*fp[0][i],tp[0][i]*fp[1][i], tp[0][i]]
A[2 * i + 1] = [0, 0, 0, -fp[0][i], -fp[1][i], -1,
tp[1][i] * fp[0][i], tp[1][i] * fp[1][i], tp[1][i]]
U, S, V = linalg.svd(A)
H = V[8].reshape((3,3))
# 反归一化
H = dot(linalg.inv(C2), dot(H,C1))
# 归一化,返回
return H / H[2,2]
def HaffineFromPoints(fp, tp):
"""
计算H,仿射变换,使得 tp, fp 是经过仿射变换H 得到的,
与上面不同的是,仿射变换是只有六个自由度的,也就是说,h7=h8=0
"""
# 形状不同
if fp.shape != tp.shape:
return RuntimeError('number of points do not match')
# 对点进行归一化处理
# 映射起始点
m = mean(fp[:2], axis=1)
maxstd = max(std(fp[:2], axis=1)) + 1e-9
C1 = diag([1 / maxstd, 1 / maxstd, 1])
C1[0][2] = -m[0] / maxstd
C1[1][2] = -m[1] / maxstd
fp_cond = dot(C1, fp)
# 映射对应点
m = mean(tp[:2], axis=1)
C2 = C1.copy()
C2[0][2] = -m[0] / maxstd
C2[1][2] = -m[1] / maxstd
tp_cond = dot(C2, tp)
A = concatenate((fp_cond[:2],tp_cond[:2]), axis = 0)
U, S, V = linalg.svd(A.T)
# 创建B、C
tmp = V[:2].T
B = tmp[:2]
C = tmp[2:4]
tmp2 = concatenate((dot(C, linalg.pinv(B)),zeros((2,1))), axis = 1)
H = vstack((tmp2, [0, 0, 1]))
# 反归一化
H = dot(linalg.inv(C2), dot(H, C1))
return H / H[2,2]
if name == 'main':
pointX = []
pointY = []
for i in range(4):
for j in range(4):
pointX.append(i)
pointY.append(j)
Points = array([pointX, pointY])
Points = makeHomog(Points)
# 仿射变换矩阵
rtMatrix = array(
[[0.5, 0, 1],
[0, 0.5, 1],
[0, 0, 1]]
)
changedPoints = flact(Points, rtMatrix)
plotTwoPoints(Points, changedPoints)
print(hFromPoints(Points, changedPoints))
print(HaffineFromPoints(Points, changedPoints))
show()
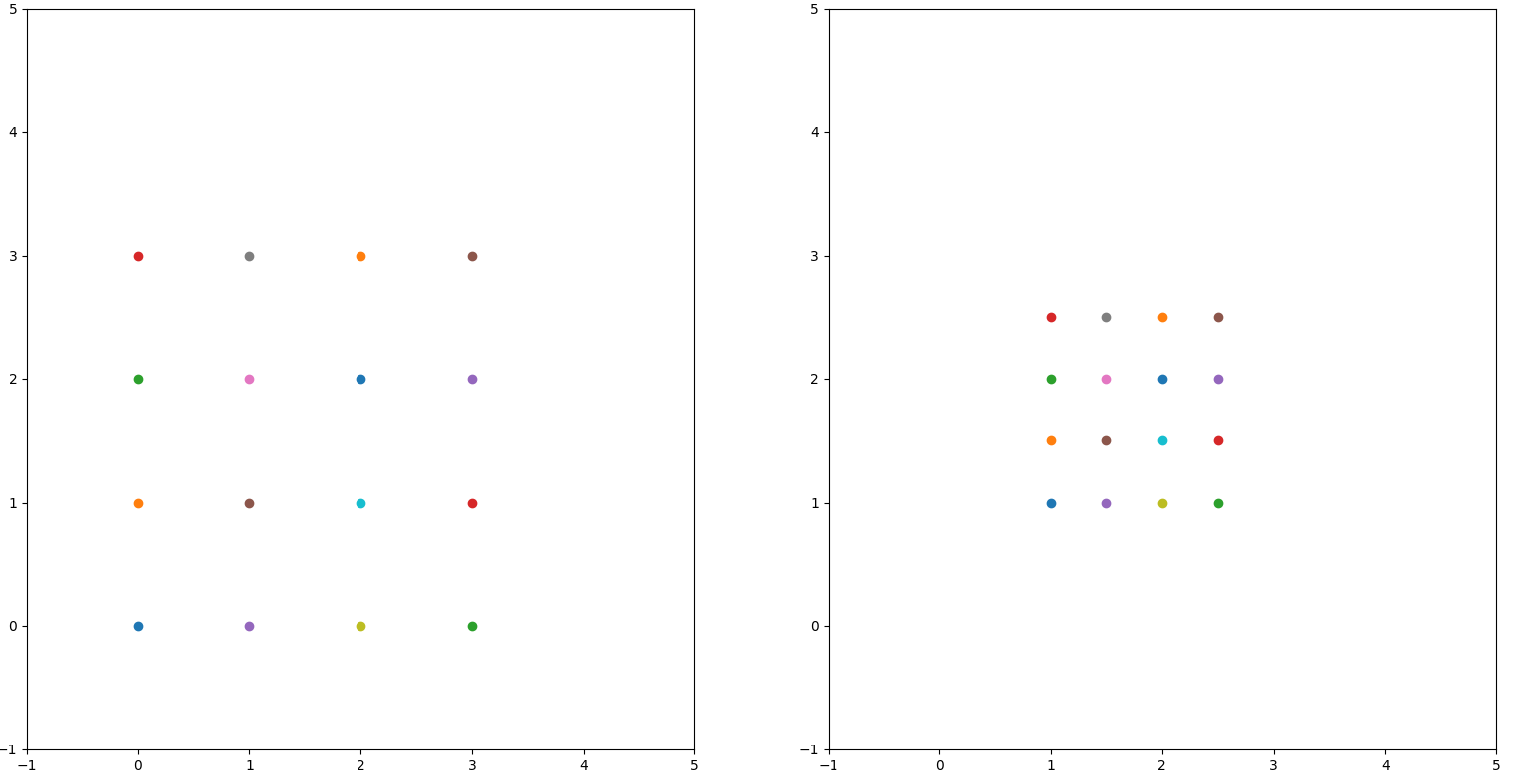
结果
在刚才的代码中,我们使用仿射变换矩阵:
进行变化,我们利用一组点变换前后的状态,求仿射变换矩阵。得到的结果如下:
[[ 5.00000000e-01 1.20777603e-16 1.00000000e+00] [-1.13154271e-16 5.00000000e-01 1.00000000e+00] [ 2.45515188e-17 1.40739819e-17 1.00000000e+00]]
[[ 5.00000000e-01 6.07529133e-16 1.00000000e+00] [-1.11022302e-16 5.00000000e-01 1.00000000e+00] [ 0.00000000e+00 0.00000000e+00 1.00000000e+00]]
其中,上面的结果是8自由度下的解,而下面的结果是6自由度下的解。我们可以发现结果非常完美。但是这是否是由于我门取了4*4=16个点的原因呢?于是我降低了采样数量,从原来的采样间隔为1降低到采样间隔为2,并进行观察。在此情况下,我们只取4个点,结果如下:
[[ 5.00000000e-01 -3.12481436e-16 1.00000000e+00] [-5.50986389e-16 5.00000000e-01 1.00000000e+00] [-3.84592537e-16 -9.61481342e-17 1.00000000e+00]]
[[ 5.00000000e-01 -1.79637859e-16 1.00000000e+00] [ 1.11022302e-16 5.00000000e-01 1.00000000e+00] [ 0.00000000e+00 0.00000000e+00 1.00000000e+00]]
我们发现,虽然结果与上一组相比较下,偏差相对较大,但是误差仍然在可以忽略的范围内,总体来说结果非常理想。